研究テーマ
深層学習とデータ生成の手法を用いて、コンピュータグラフィックス(CG)やコンピュータビジョン(CV)に関する研究を行っています。 また、仮想現実(VR)や拡張現実(AR)における重要かつ難しい課題にCG/CVの手法を活用して取り込んでいます。
画像処理 博士
助教授 (Assistant Professor)
早稲田大学 森島研究室

2022年9月で博士号取得。
現在、早稲田大学先進理工学部の物理・応用物理学科で
助教授(Assistant Professor)として働いています。
森島研究室に所属、コンピューターグラフィックスとコンピュータービションに関する研究を行っています。
深層学習とデータ生成の手法を用いて、コンピュータグラフィックス(CG)やコンピュータビジョン(CV)に関する研究を行っています。 また、仮想現実(VR)や拡張現実(AR)における重要かつ難しい課題にCG/CVの手法を活用して取り込んでいます。
中国語 - ネイティブレベル 英語 - ほぼネイティブレベル (GREスコア325, TOEICスコア985)
日本語 - ビジネスレベル (JLPT N1) フランス語 - 日常会話レベル (CEFR A2)
熟練: Python, HTML/CSS, SQL その他: C++, C#, Java, Javascript
PyTorch, Torchvision, Tensorflow, OpenCV Git, SharePoint WordPress, Unity3D, Arduino
物体分類、領域分類、深度予測、シーン再構成、姿勢推定、画風変換、データ合成
Microsoft Office 365 (Access, SharePoint), Adobe Creative Cloud (Lightroom Classic, Photoshop, Illustrator, After Effects, Premiere Pro, Audition, InDesign), Ableton, Vocaloid, Blender
Feng, Q. , Kayukawa, S., Wang, X., Takagi, H., & Asagawa, C. (Under Review). STAMP: Scale-aware TActile-Map Printing for Accessible Spatial Understanding and Navigation. In 2026 CHI Conference on Human Factors in Computing Systems.
Feng, Q. , Kayukawa, S., Wang, X., Takagi, H., & Asagawa, C. (2025). A Scale-Aware Method for Generating 3D-Printable Tactile Maps. The 33rd Workshop on Interactive Systems and Software.
Iwakata, S., Oshima, R., Tsunashima, H., Feng, Q., Kataoka, H., & Morishima, S. (2025). Viewpoint-dependent 3D Visual Grounding for Mobile Robots. In 2025 IEEE International Conference on Image Processing.
Inoue, R., Feng, Q. , & Morishima, S. (2025). SynchroDexterity: Rapid Non-Dominant Hand Skill Acquisition with Synchronized Guidance in Mixed Reality. In 2025 IEEE conference on virtual reality and 3D user interfaces (VR). IEEE.
Nishizawa, T., Tanaka, K., Hirata, A., Yamaguchi, S., Feng, Q. , Hamanaka, M., & Morishima, S. (2025). SyncViolinist: Music-Oriented Violin Motion Generation Based on Bowing and Fingering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision.
Higasa, T., Tanaka, K., Feng, Q. , & Morishima, S. (2024). Keep Eyes on the Sentence: An Interactive Sentence Simplification System for English Learners Based on Eye Tracking and Large Language Models. CHI EA '24: Extended Abstracts of the 2024 CHI Conference on Human Factors in Computing Systems.
Feng, Q. , & Morishima, S. (2024). Projection-Based Monocular Depth Prediction for 360 Images with Scale Awareness. Visual Computing Symposium 2024.
Inoue, R., Feng, Q., & Morishima, S. (2024). Non-Dominant Hand Skill Acquisition with Inverted Visual Feedback in a Mixed Reality Environment. Visual Computing Symposium 2024.
Feng, Q. , Shum, H. P., & Morishima, S. (2023). Enhancing perception and immersion in pre-captured environments through learning-based eye height adaptation. 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR).
Feng, Q. , Shum, H. P., & Morishima, S. (2023). Learning Omnidirectional Depth Estimation from Internet Videos. In Proceedings of the 26th Meeting on Image Recognition and Understanding.
Higasa, T., Tanaka, K., Feng, Q., & Morishima, S. (2023). Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability. The 25th International Conference on Multimodal Interaction (ICMI).
Kashiwagi, S., Tanaka, K., Feng, Q., & Morishima, S. (2023). Improving the Gap in Visual Speech Recognition Between Normal and Silent Speech Based on Metric Learning. INTERSPEECH 2023.
Oshima, R., Shinagawa, S., Tsunashima, H., Feng, Q., & Morishima, S. (2023). Pointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue. ICCV '23 Workshop and Challenge on Vision and Language Algorithmic Reasoning (ICCVW).
Feng, Q. , Shum, H. P., & Morishima, S. (2022). 360 Depth Estimation in the Wild-The Depth360 Dataset and the SegFuse Network. In 2022 IEEE conference on virtual reality and 3D user interfaces (VR). IEEE.
Feng, Q. , Shum, H. P., & Morishima, S. (2021). Bi-projection-based Foreground-aware Omnidirectional Depth Prediction. Visual Computing Symposium 2021.
Feng, Q. , Shum, H. P., Shimamura, R., & Morishima, S. (2020). Foreground-aware Dense Depth Estimation for 360 Images. International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision 2020.
Shimamura, R., Feng, Q., Koyama, Y., Nakatsuka, T., Fukayama, S., Hamasaki, M., ... & Morishima, S. (2020). Audio–visual object removal in 360-degree videos. Computer Graphics International 2020.
Feng, Q. , Shum, H. P., & Morishima, S. (2018, November). Resolving occlusion for 3D object manipulation with hands in mixed reality. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology.
Feng, Q. , Nozawa, T., Shum, H. P., & Morishima, S. (2018, August). Occlusion for 3D Object Manipulation with Hands in Augmented Reality. In Proceedings of The 21st Meeting on Image Recognition and Understanding.
Nozawa, N., Shum, H. P., Feng, Q., Ho, E. S., & Morishima, S. (2021). 3D car shape reconstruction from a contour sketch using GAN and lazy learning. The Visual Computer, 1-14.
Feng, Q. , Shum, H. P., & Morishima, S. (2020). Resolving hand‐object occlusion for mixed reality with joint deep learning and model optimization. Computer Animation and Virtual Worlds, 31(4-5), e1956.
Feng, Q. , Shum, H. P., Shimamura, R., & Morishima, S. (2020). Foreground-aware Dense Depth Estimation for 360 Images., Journal of WSCG, 28(1-2), 79-88.
Shimamura, R., Feng, Q., Koyama, Y., Nakatsuka, T., Fukayama, S., Hamasaki, M., ... & Morishima, S. (2020). Audio–visual object removal in 360-degree videos. The Visual Computer, 36(10), 2117-2128.
Githubで公開されているプロジェクト:

SyncViolinistは,音声入力のみを用いて同期したバイオリン演奏動作を生成する多段階のエンドツーエンドフレームワークである.本フレームワークは,演奏のグローバルな特徴と細部の特徴を効果的に捉える課題を克服することに成功している.

ネット上の豊富な360度パノラマ動画を活用し、大規模なRGB・深度の学習データを生成する方法を提案した。 さらに、360度画像に対する単眼的深度予測を学習するマルチタスクモデルを提案した。実験の結果、予測は効率的で正確であることが確認した。
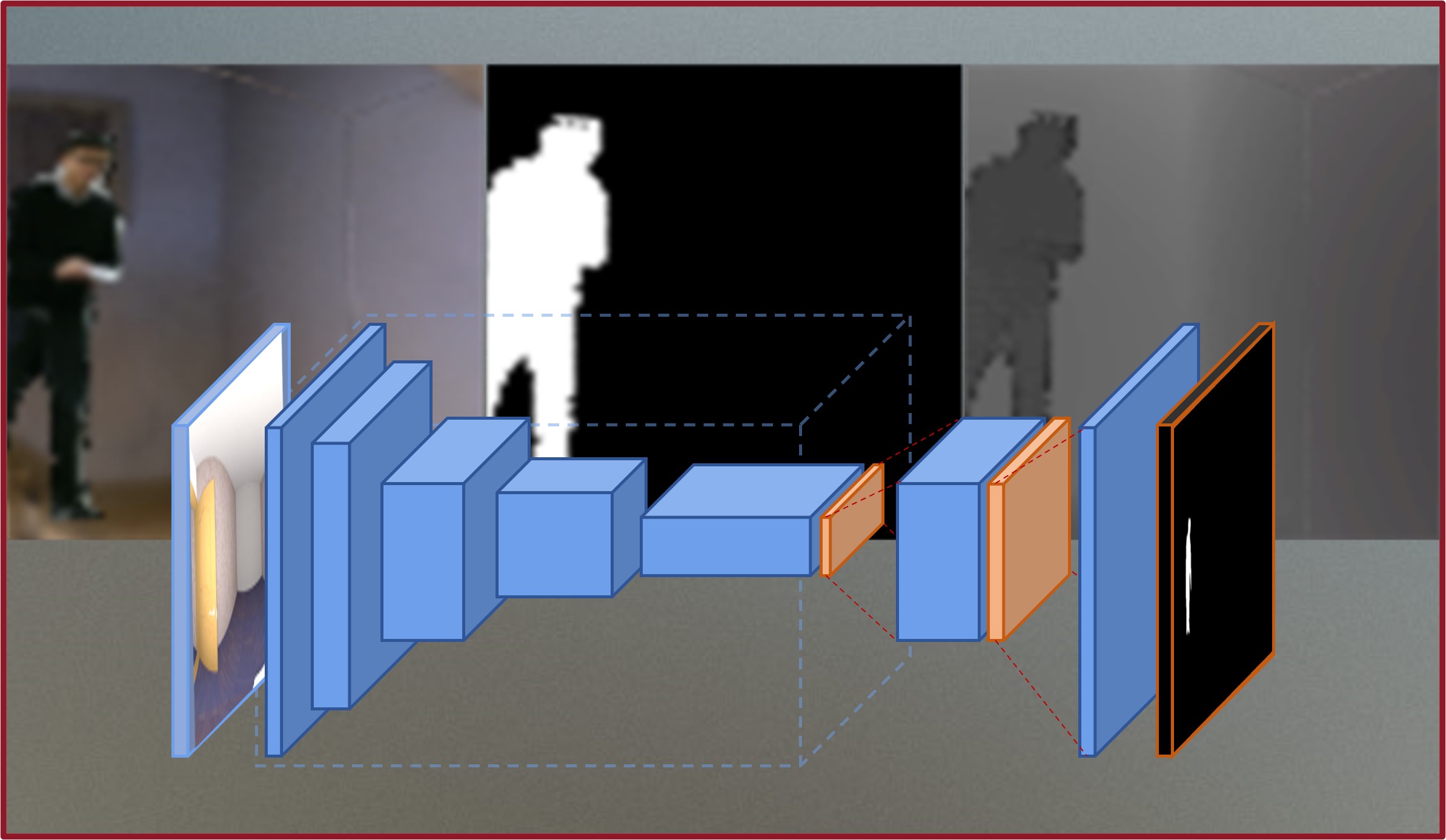
360度のRGB・深度データセットに現実的な前景を追加し、大規模な全景を意識する学習データを生成した。 また、前景の深度・セグメンテーションを推定する補助ネットワークを提案し、より精度の高い推定を実現した。

強いオクルージョン下での姿勢追跡とセグメンテーションのために、CycleGANを用いたRGBD手と物体のデータセットを提案した。 そして、最適化を用いて拡張現実におけるオクルージョン問題を実時間で解決した。
電話番号: +81-3-5286-3510
FAX: +81-3-5286-3510
住所: 55N406 3-4-1 Okubo, Shinjuku-ku, Tokyo, 169-0072
メール: fengqi[at]ruri.waseda.jp