研究方向
我的研究方向主要是通過基於深度學習的方法解決不同的計算機圖形和計算機視覺問題。 除此之外,我也熱衷於活用CG/CV的方法來解決一些當前虛擬現實(VR)和增強現實(AR)應用中存在的一系列實際問題。
圖像處理和機器視覺 Ph.D.
助理教授
早稻田大學, 森島研究室

我於2022年9月獲得圖像處理專業的博士學位。
現在在位於日本東京的早稻田大學
先進理工學部擔任助理教授(Assistant Professor)職位。
目前隸屬於森島研究室進行圖像處理和機器視覺相關的研究工作。
我的研究方向主要是通過基於深度學習的方法解決不同的計算機圖形和計算機視覺問題。 除此之外,我也熱衷於活用CG/CV的方法來解決一些當前虛擬現實(VR)和增強現實(AR)應用中存在的一系列實際問題。
中文 - 母語水平 英語 - 熟練掌握 (GRE得分325)
日語 - 熟練掌握 (JLPT N1) 法語 - 簡單對話 (CEFR A2)
熟練使用: Python, HTML/CSS, SQL 較為熟悉: C++, C#, Java, Javascript
PyTorch, Torchvision, Tensorflow, OpenCV Git, SharePoint WordPress, Unity3D, Arduino
對象分類, 圖像語義分割, 深度預測, 場景重建, 動作預測, 畫風轉換, 合成訓練集
Microsoft Office 365 (Access, SharePoint), Adobe Creative Cloud (Lightroom Classic, Photoshop, Illustrator, After Effects, Premiere Pro, Audition, InDesign), Ableton, Vocaloid, Blender
Feng, Q. , Kayukawa, S., Wang, X., Takagi, H., & Asagawa, C. (Under Review). STAMP: Scale-aware TActile-Map Printing for Accessible Spatial Understanding and Navigation. In 2026 CHI Conference on Human Factors in Computing Systems.
Feng, Q. , Kayukawa, S., Wang, X., Takagi, H., & Asagawa, C. (2025). A Scale-Aware Method for Generating 3D-Printable Tactile Maps. The 33rd Workshop on Interactive Systems and Software (Japan).
Iwakata, S., Oshima, R., Tsunashima, H., Feng, Q., Kataoka, H., & Morishima, S. (2025). Viewpoint-dependent 3D Visual Grounding for Mobile Robots. In 2025 IEEE International Conference on Image Processing.
Inoue, R., Feng, Q. , & Morishima, S. (2025). SynchroDexterity: Rapid Non-Dominant Hand Skill Acquisition with Synchronized Guidance in Mixed Reality. In 2025 IEEE conference on virtual reality and 3D user interfaces (VR). IEEE.
Nishizawa, T., Tanaka, K., Hirata, A., Yamaguchi, S., Feng, Q. , Hamanaka, M., & Morishima, S. (2025). SyncViolinist: Music-Oriented Violin Motion Generation Based on Bowing and Fingering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision.
Higasa, T., Tanaka, K., Feng, Q. , & Morishima, S. (2024). Keep Eyes on the Sentence: An Interactive Sentence Simplification System for English Learners Based on Eye Tracking and Large Language Models. CHI EA '24: Extended Abstracts of the 2024 CHI Conference on Human Factors in Computing Systems.
Feng, Q. , & Morishima, S. (2024). Projection-Based Monocular Depth Prediction for 360 Images with Scale Awareness. Visual Computing Symposium 2024.
Inoue, R., Feng, Q., & Morishima, S. (2024). Non-Dominant Hand Skill Acquisition with Inverted Visual Feedback in a Mixed Reality Environment. Visual Computing Symposium 2024.
Feng, Q. , Shum, H. P., & Morishima, S. (2023). Enhancing perception and immersion in pre-captured environments through learning-based eye height adaptation. 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR).
Feng, Q. , Shum, H. P., & Morishima, S. (2023). Learning Omnidirectional Depth Estimation from Internet Videos. In Proceedings of the 26th Meeting on Image Recognition and Understanding.
Higasa, T., Tanaka, K., Feng, Q., & Morishima, S. (2023). Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability. The 25th International Conference on Multimodal Interaction (ICMI).
Kashiwagi, S., Tanaka, K., Feng, Q., & Morishima, S. (2023). Improving the Gap in Visual Speech Recognition Between Normal and Silent Speech Based on Metric Learning. INTERSPEECH 2023.
Oshima, R., Shinagawa, S., Tsunashima, H., Feng, Q., & Morishima, S. (2023). Pointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue. ICCV '23 Workshop and Challenge on Vision and Language Algorithmic Reasoning (ICCVW).
Feng, Q. , Shum, H. P., & Morishima, S. (2022). 360 Depth Estimation in the Wild-The Depth360 Dataset and the SegFuse Network. In 2022 IEEE conference on virtual reality and 3D user interfaces (VR). IEEE.
Feng, Q. , Shum, H. P., & Morishima, S. (2021). Bi-projection-based Foreground-aware Omnidirectional Depth Prediction. Visual Computing Symposium 2021.
Feng, Q. , Shum, H. P., Shimamura, R., & Morishima, S. (2020). Foreground-aware Dense Depth Estimation for 360 Images. International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision 2020.
Shimamura, R., Feng, Q., Koyama, Y., Nakatsuka, T., Fukayama, S., Hamasaki, M., ... & Morishima, S. (2020). Audio–visual object removal in 360-degree videos. Computer Graphics International 2020.
Feng, Q. , Shum, H. P., & Morishima, S. (2018, November). Resolving occlusion for 3D object manipulation with hands in mixed reality. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology.
Feng, Q. , Nozawa, T., Shum, H. P., & Morishima, S. (2018, August). Occlusion for 3D Object Manipulation with Hands in Augmented Reality. In Proceedings of The 21st Meeting on Image Recognition and Understanding.
Nozawa, N., Shum, H. P., Feng, Q., Ho, E. S., & Morishima, S. (2021). 3D car shape reconstruction from a contour sketch using GAN and lazy learning. The Visual Computer, 1-14.
Feng, Q. , Shum, H. P., & Morishima, S. (2020). Resolving hand‐object occlusion for mixed reality with joint deep learning and model optimization. Computer Animation and Virtual Worlds, 31(4-5), e1956.
Feng, Q. , Shum, H. P., Shimamura, R., & Morishima, S. (2020). Foreground-aware Dense Depth Estimation for 360 Images., Journal of WSCG, 28(1-2), 79-88.
Shimamura, R., Feng, Q., Koyama, Y., Nakatsuka, T., Fukayama, S., Hamasaki, M., ... & Morishima, S. (2020). Audio–visual object removal in 360-degree videos. The Visual Computer, 36(10), 2117-2128.
發布於Github上的開源項目:

我們提出SyncViolinist這一個多階段的端對端架構,可僅從音訊輸入產生同步的小提琴演奏動作。它成功克服了捕捉全局和細微奏特徵的挑戰。

我們首先提出了一種從豐富的互聯網360度全景視頻中生成大量匹配的顏色/深度訓練數據的方法。 其次我們提出了一個多任務網絡來學習360度圖像的單眼深度預測。實驗結果高效且準確。
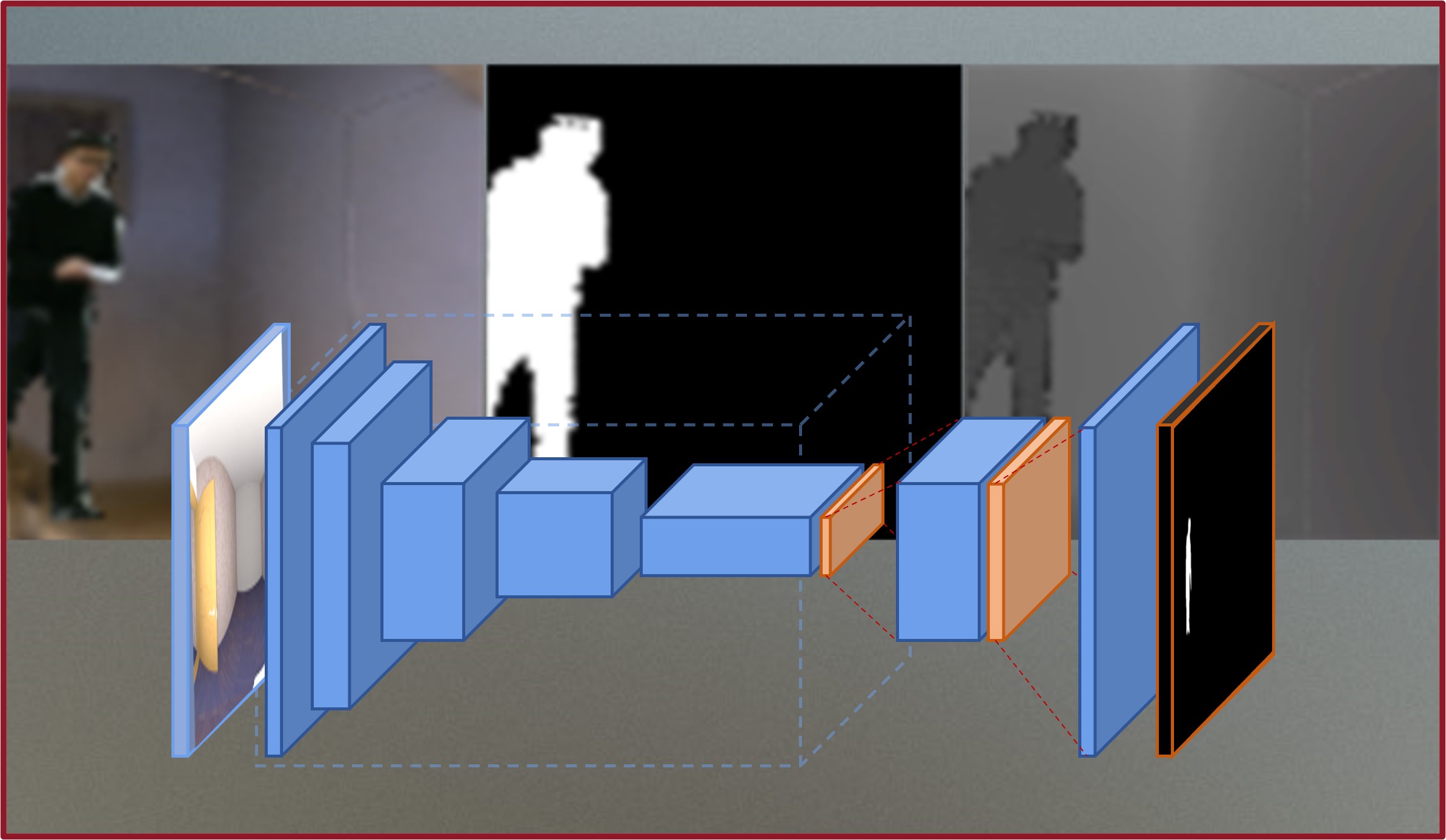
我們首先通過圖像處理的方法來獲取了不同樣式的前景顏色/深度的訓練數據。用新穎的方法將其合成至現有的360度圖像的訓練集後, 我們繼而提出了一個多任務輔助網絡和損失函數,成功克服了現有方法對前景對象預測結果較差的問題。

為了解決混合現實(MR)中常見的由於場景結構未知而導致的手與物體間的遮蔽問題,我們通過CycleGAN生成了大規模 真實且準確的顏色/深度/姿勢訓練集,然後提出了一個實時的基於姿勢追蹤和語義分割的多任務網絡。使用者實驗和量化分析都獲得了很好的結果。
電話: +81-3-5286-3510
傳真: +81-3-5286-3510
地址: 55N406 3-4-1 Okubo, Shinjuku-ku, Tokyo, 169-0072
郵件: fengqi[at]ruri.waseda.jp